
최근 팀 프로젝트를 진행하면서 처음으로 클라우드 구축 / 운영을 담당하였습니다. 약 한달 동안 팀 동료들과 함께 밤을 새기도, 떄로는 교육장에서 잠을 자고, 에러를 해결하며 숨 가쁜 시간을 보냈습니다. 지금 그 떄를 돌이켜보면 해당 프로젝트를 통해 스스로 성장할 수 있었고, 아쉬운 점도 많습니다. 특히 프로젝트 후반에 중국으로부터 Brute force attack 을 당했을때는 정말 당혹스러웠습니다.
이번 글을 통해 프로젝트를 다시 한번 정리 해보고 , 어떤점이 부족했는지를 분석해보려 합니다.
1. 프로젝트 설명
| 팀 프로젝트 | 화장품을 보다 (화장품 유통기한 관리/추천 AI 서비스) |
유형 | 팀 프로젝트(4명) | |
| 담당 | AWS 인프라 구축 및 운영 | |||
| Tool | Python, Naver clova, AWS Services | |||
| 개발 내용 | 사용자가 화장품 사진을 전송하면 , 텍스트를 분석하여 유통기한과 사용기한을 계산하고 , 유통기한이 임박한 화장품에 대한 개인별 화장품 추천 서비스 | |||

본 프로젝트는 자신이 갖고 있는 화장품의 유통기한을 파악하기 힘들다는 불편함에서 시작했습니다. 비록 알고 있더라도 여러 개의 화장품의 유통기한을 일일이 기억하기란 쉽지 않습니다. 따라서 저희 팀은 이러한 사용자의 불편함을 덜어주고자 해당 프로젝트를 기획하게 되었습니다.
프로젝트 목표
화장품의 유통 기한을 제대로 알지 못해 피부 트러블을 경험한 사람들을 위해, 사용자가 보다 안전하게 화장품을 사용할 수 있도록 하였습니다. 또한 사용 기한이 임박한 화장품에 대한 추천 서비스를 통해 쉽게 화장품을 구매할 수 있도록 하였습니다.
서비스 대상
1. 화장품을 바르는 모든 사용자
2. 사용 기한에 따라 기지고 있는 화장품을 관리하고 싶은 사용자
3. 피부타입에 따른 추천받고 싶은 사용자
2. 인프라 구축 및 운영
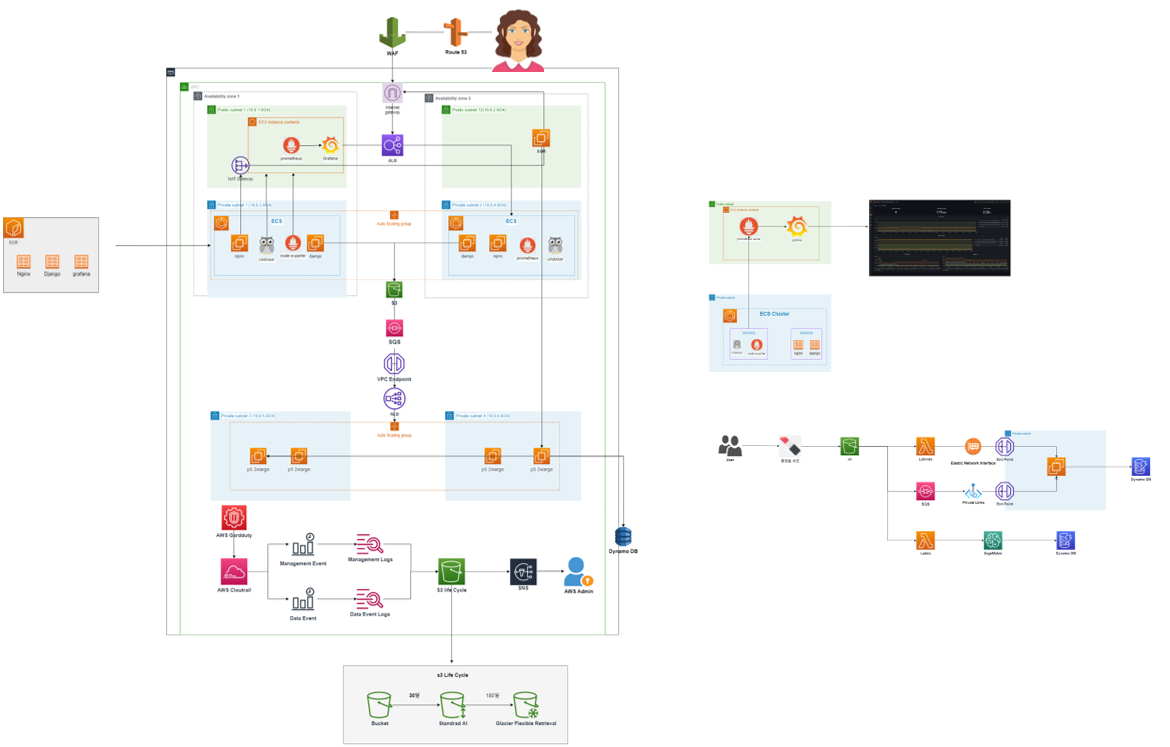
위 그림은 프로젝트 초기에 제가 draw.io를 통해 그린 설계도입니다. 이제부터 제가 인프라를 구축 및 운영하면서 어떤 점을 신경쓰고, 부족했는지 적어보려 합니다.
2.1 ECS 기반 인프라 모델을 선정한 이유
사실 저희 팀 프로젝트 주제가 처음부터 화장품 관련은 아니었습니다. 원래는 카메라를 통하여 사용자의 실시간 운동을 분석하여 자세 교정 서비스를 생각하고 있었습니다. 그러나 저희 팀 기술 실력으로는 도저히 핵심 기능을 구현할 수가 없어 포기했습니다. 이 때문에 프로젝트 전체 일정이 약 2주간 밀렸습니다.이후 약 한달을 남긴 시점에서, 저희 팀은 빠듯한 일정 속에서 프로젝트를 마치기 위해서는 최소한의 핵심 아이디어로 빠르게 구축하고, 사용자의 피드백을 받으며 개선하는 방법인 MVP(Minimum Viable Product)를 따르기로 했습니다.

MVP라는 목적을 고려해 보았을 때, AWS ECS는 다음과 같은 이점이 있기에 선택하게 되었습니다.
- 개발팀과 회의 결과 Django framework 에 익숙치 않아 잦은 코드 변경 및 업데이트가 예상되었으므로 CI / CD 를 활용하여 ECS를 관리한다면 지속적인 업데이트 및 배포 가능
- Nginx,Django,Gunicorn 총 3개의 기술을 써야 하는 상황에서 하나의 서버에 집중시키기보다는, 각각 컨테이너 별로 관리한다면 추후 문제가 생겼을 시 빠르게 해결 가능
2.2 ECS 기반 인프라 모델 모니터링
당시 프로젝트 예산은 총 300$ 였으므로 비용을 최대한 효율적으로 사용했어야 했습니다. AWS Cloudwatch를 통해 ECS를 모니터링 할 수도 있었지만 Cloudwatch 또한 사용량에 따라 비용을 지불해야 하기에 제외하였습니다. 이러한 상황에서 Prometheus와 Grafana는 참 매력적이었습니다. 오픈소스이기 때문에 Cloudwatch 대비 비용절감을 할 수 있었고, 실간 리소스 상태를 그라파나의 대시보드를 통해 커스터마이징 할 수 있었습니다.

모니터링 서버를 구축하고 실제로 친구들에게 저희 팀 프로젝트의 웹 사이트 방문부탁을 해 보았습니다. 몇 초 후 위 사진과 같이 그래프가 치솟는 것을 확인할 수 있었습니다. Prometheus와 Grafana는 평소에 제가 꼭 사용해보고 싶었던 기술이었기에 실시간 모니터링이 정상작동 했을때는 정말 뿌듯함을 느꼈습니다.
아쉬운 점...
프로메테우스와 그라파나를 모니터링 하던 중 하나의 아이디어가 떠올랐습니다. '만약 사용자의 데이터를 Database에 저장한 후, 그라파나로 연동할 수 있을까?'. 실제로 관련 사례 조사를 통해 마케팅에서 그라파나 대시보드를 통해 인사이트를 얻고 활용한다는 것을 알게되었습니다. 저희 팀은 Dynamodb를 사용하고 있었기에 사용자의 회원가입,서비스 이용 데이터등을 그라파나로 시각화 하고 싶었지만 프로젝트 일정 상 시간이 부족하여 도전해보지 못한것이 참 아쉽게 느껴집니다.
2.3 AWS Cloudformation을 통한 인프라 구축

AWS Cloudformation 을 이용하여 인프라를 구축한것은 새로운 기술에 대한 욕심이 제일 컸습니다. 프로젝트 일정 상 교육에서 배우지 않았던 새로운기술을 접목 한다는 것은 위험한 선택이었으나, 개인적으로 코드를 통해 인프라를 구축한다는 것이 재미있어 꼭 해보고 싶었습니다. 템플릿을 이용하여 인프라의 약 80% 를 구축하였습니다.
- VPC 환경
- 보안 그룹
- 머신러닝 & 딥러닝 분석용 EC2 인스턴스
- ECR / ECS
- Prometheus & Grafana
- Application Load Balancing
아쉬운 점...
초반에 템플릿을 yaml code 로 작성하면서 들여쓰기,오타로 인하여 정상적으로 스택이 업데이트 되지 않아 고생을 많이 했습니다. 이런 기초적인 실수로 인하여 문제가 발생했다는 것은 뼈 아픈 실수라고 생각합니다. 이 경험을 통해 급할수록 천천히, 정확한 습관을 길러야 된다는 것을 깨달았습니다. 기술적으로는 Cloudformation의 changeset 과 drfit를 사용하지 못한것이 아쉬웠습니다. 실제로 제가 작성한 템플릿의 스택 구축 과정에서 문제가 발생할 경우 코드를 수정하여 다시 스택을 구축하는 비효율적인 과정을 거쳤습니다. change set 과 drift 기술을 사용했더라면 스택 업데이트 시에 실행중인 리소스에 미치는 영향을 확인할 수 있고, 오류가 발생하면 마지막 정상 스택 단계로 되돌릴 수 있지 않았을까 합니다.
2.4 Cloudtrail을 통한 규정 준수, 운영 및 위험 감사 활성화
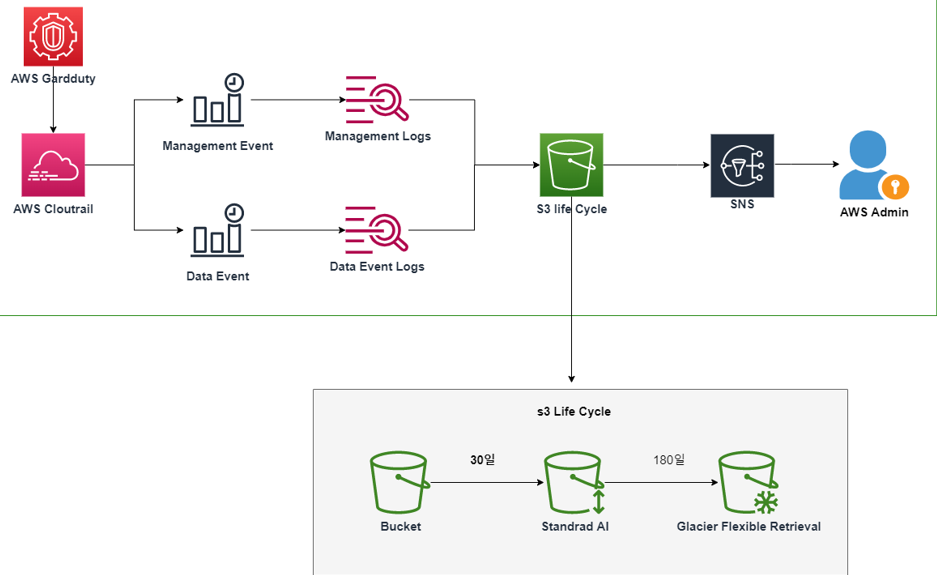
프로젝트 당시 인터넷 기사를 통해 AWS 계정 혹은 EC2 인스턴스를 해킹하여 비트코인 채굴이 급증하고 있다는 것을 읽었습니다. 프로젝트 인프라를 관리 담당을 맡고 있는 저는 이에 경각심을 느끼고 Cloudtrail을 활성화를 통해 대응 방안을 마련했습니다. 먼저 Cloudtrail 활성화를 통해 총 2개의 이벤트 Log를 수집하였습니다.
- Mangement log: AWS 계정의 리소스에 수행되는 관리 작업( ex S3 버킷 생성, IAM)
- DataEvent log: AWS 계정의 리소스 내에서 수행되는 리소스 작업(ex S3 API, lambda)
해당 프로젝트 활동은 모두 서울 리전에서 관리되고 있었지만, 다른 리전의 경우 일일이 관리하기 쉽지 않았기 때문에 서울을 포함한 모든 리전의 이벤트 로그가 실시간으로 S3 에 수집하도록 설정하였습니다. 또한 실시간 이벤트 로그가 S3에 저장될 경우 SNS을 통하여 인프라 관리자인 저에게 메일이 수신되도록 설정하였습니다.

아쉬운 점...
Cloudtrail을 활성화 한 후 인프라를 운영하면서 실제로 모든 리전에 대해 어떠한 활동이 있었는지 확인할 수 있었습니다. 그러나 말 그대로 메일을 통하여 확인 수준에 그쳤습니다. 만약 AWS Athena를 이용하여 이벤트 로그들을 쿼리를 통해 분석하고, 더 나아가 AWS Quicksight와 통합하여 이벤트 로그들을 시각화 했더라면, AWS 계정에서 어떠한 일들이 일어나고 있는지 더욱 쉽게 확인이 가능했을 것입니다.
2.5 EC2 인스턴스에 Brute force attack 발생
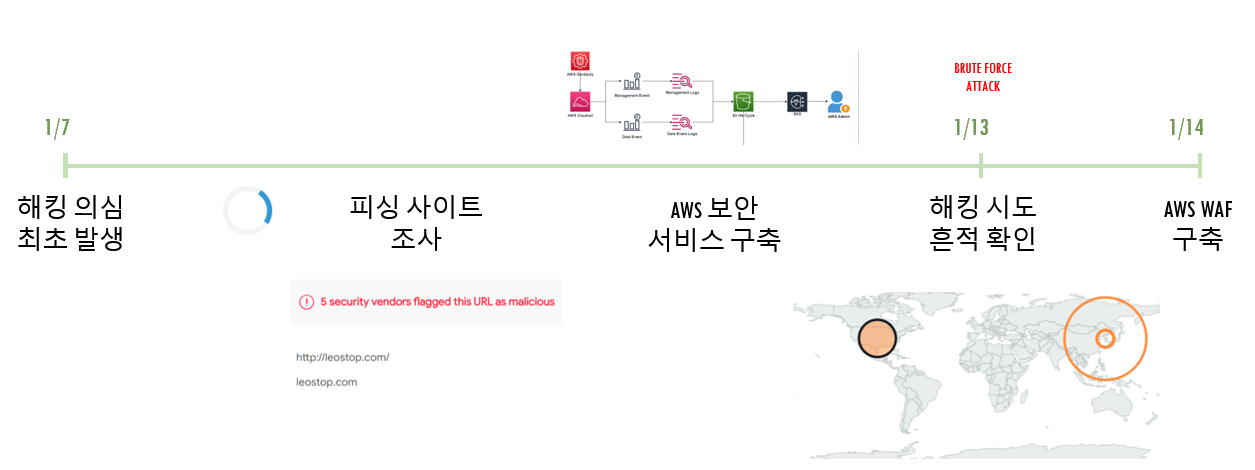
프로젝트 마감 일주일 전, EC2 인스턴스에 중국으로 부터 Brute force Attack 을 당했습니다. 해킹 시도를 당한적은 처음이라 저와 팀원 모두 당혹감을 감추지 못했습니다. 사실 해킹 징후는 며칠 전부터 발생하고 있었습니다. 당시 개발팀에서는 인터넷에서 부트스트랩 코드를 다운받아 이를 활용하여 웹을 구축했습니다. 그러나 언제부터인가 leostop.com 이라는 사이트로 자동으로 리다이렉션 되는 현상이 발생하였고, 개발팀의 소스코드를 조사해 본 결과 Javascript 코드가 원인이라는 것을 알게되었습니다. 상황이 심각한지라 팀 회의를 통해 다음과 같은 두 가지 의견이 제시되었습니다.
- 부트스트랩 코드 기반 웹 사이트 구축을 포기하고, 새롭게 웹 사이트 구축
- 문제가 되는 Javascript 코드를 삭제한 후 그대로 진행

인프라 관리자인 저는 문제가 되는 부트스트랩 코드를 계속 사용한다는 것은 리스크가 너무 크다고 판단하였지만, 개발팀과 회의를 통해 프로젝트 마감을 일주일 남긴 시점에서 HTML, CSS 코드를 새롭게 짜는것은 불가능 하다는 결론을 내렸습니다. 이후 제가 우려하던대로 Guard Duty를 통해 해킹 시도가 이루어졌고, 이에 AWS WAF, Detective 를 통해 악의적인 IP 활동 및 ,봇 공격등에 대한 대응방안을 마련하였습니다.
AWS WAF Rulls
- PHP RuleSet
- AnonymouslpList
- BotControllRuleSet
- CommonRuleSet
- IpReputationList
- BadInputRuleSet
아쉬운 점...
무엇보다 제가 열심히 구축한 인프라에 중국으로부터 해킹시도가 있었다는 점이 힘들었습니다. 물론 웹 혹은 앱이 인터넷에 공개되는 순간 해킹으로부터 자유로울 순 없습니다. 그러나 해킹 징조가 있었음에도 제대로 대처하지 못한것이 인프라 담당자로써 너무 아쉬웠습니다. 만약 개발팀의 소스코드를 초기부터 검사하며 구축했더라면 이번 일은 충분히 예방할 수 있었습니다. 이번 해킹 사건을 통하여 특정 영역이 아닌, 인프라 전반에 걸쳐 보안에 신경써야 된다는 것을 절실히 느낄 수 있었습니다.
글을 마치며
지금 팀 프로젝트를 회상 해 보면 참 많은 생각이 듭니다.
팀 동료들과 교육장에서 새벽까지 문제를 해결하고, 집에 가는 시간도 아까워 택시에서 휴대폰 와이파이로 해킹 모니터링도 하고... 인생에 있어서 하나의 목표를 위해 그렇게 열심히 몰두 해본적은 처음이었습니다.
무엇보다 개인이 아닌 팀 단위로 협업을 할 떄는 의사소통 능력이 정말 중요하다는 것을 느꼈습니다. 특히 해킹 이슈가 발생했을 때 개발팀과 운영팀의 관점이 달라 의견을 하나로 모아가는 과정이 어려웠습니다. 매일 수 차례 회의를 통해 배운것은 상대방의 의견을 존중해야 한다는 것입니다. 어쩌면 다소 식상한 말일지도 모릅니다. 그러나 상대방과의 대화를 할때, 아무리 자신의 기술 혹은 생각에 확신이 들 더라도 표현을 하는 순간 감정 싸움의 불 씨가 된다는 것입니다. 결과적으로 이 불 씨가 점점 커지면 프로젝트에 부정적인 영향을 줄 지도 모릅니다.
상대방과 대화를 할 때 논리있게 설득하고, 때로는 의견을 한 발 양보하는 능력이 어쩌면 기술 능력 보다 값진 능력이라고 생각합니다.
블로그를 시작하고 첫 글이다 보니 스스로 부족한 점이 참 많습니다.
누군가 이 글을 읽게 된다면, 시간내어 끝까지 읽어주셔서 감사하다는 말씀을 드리고 싶습니다.
감사합니다.
